Introduction
Many VLMs perform great on benchmarks like viusal question-answering or multi-image reasoning. Models in 2024 were predominantly trained on natural images, thus often limiting performance in other domains like visual document undestanding.
Granite Vision is a 3 billion parameters model focused on entreprise use cases with visual document understanding document content extraction and working with documents. Get the Granite Vision research paper here.
Architecture
Granite Vision was trained on 12 trillion tokens. Dataset for it’s training is constanlty curated by Granite Team but not open sourced. It contained 13 million images and 80 milllion instructions such as: document question-answering, scene understanding key-value extraction, text grounding, layout parsing, captioning, UI understanding, code comprehension.
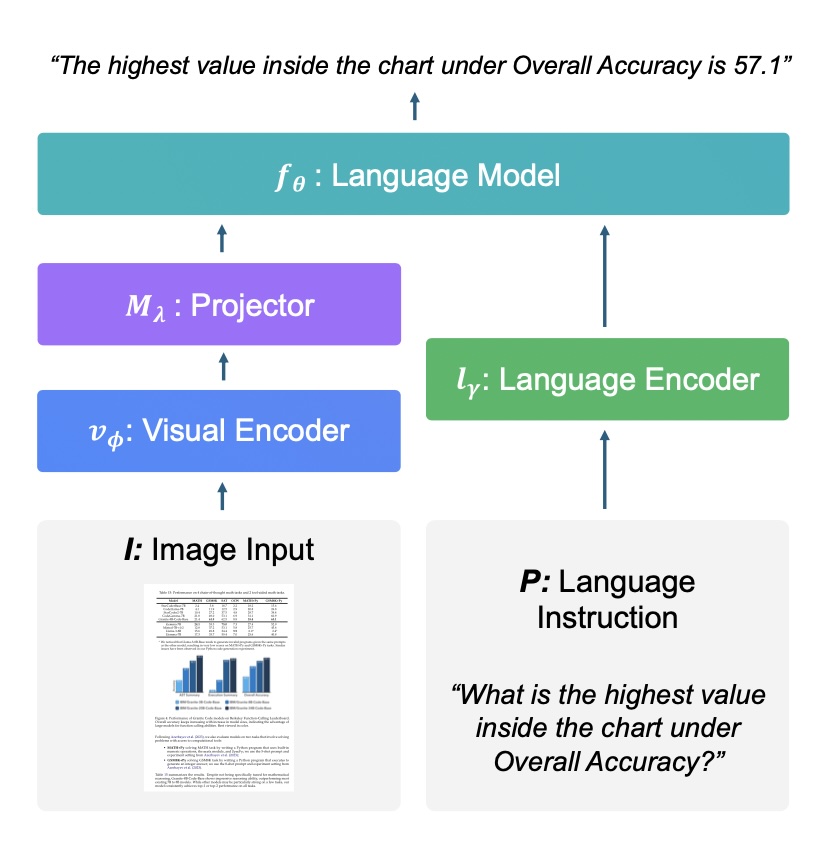
Granite Vision model has two modalities, so it has two encoders: text encoder, and vision encoder with projector that ’translates’ image encodings to text. Image encoder uses SigLIP architecture (an advanced CLIP-like vision transformer). The input resolution is 384 × 384 pixels per patch. Important technique used here is concatenating features from multiple layers instead of just using last layer. This allows the model to ‘see’ details, high level features, and different color scales of the input image. Another jig is AnyRes that solves the problem of hard to read small letters, dense table, etc., in 384 X 384 resolution. AnyRes samples input image at multiple resoultions, by splitting the image on smaller patches, and fed througth visual encoder. This allows the model to learn and generalize across scales. Concatenating and AnyRes are especially useful for document understanding, which the main use case for Granite Vision.
Datasets
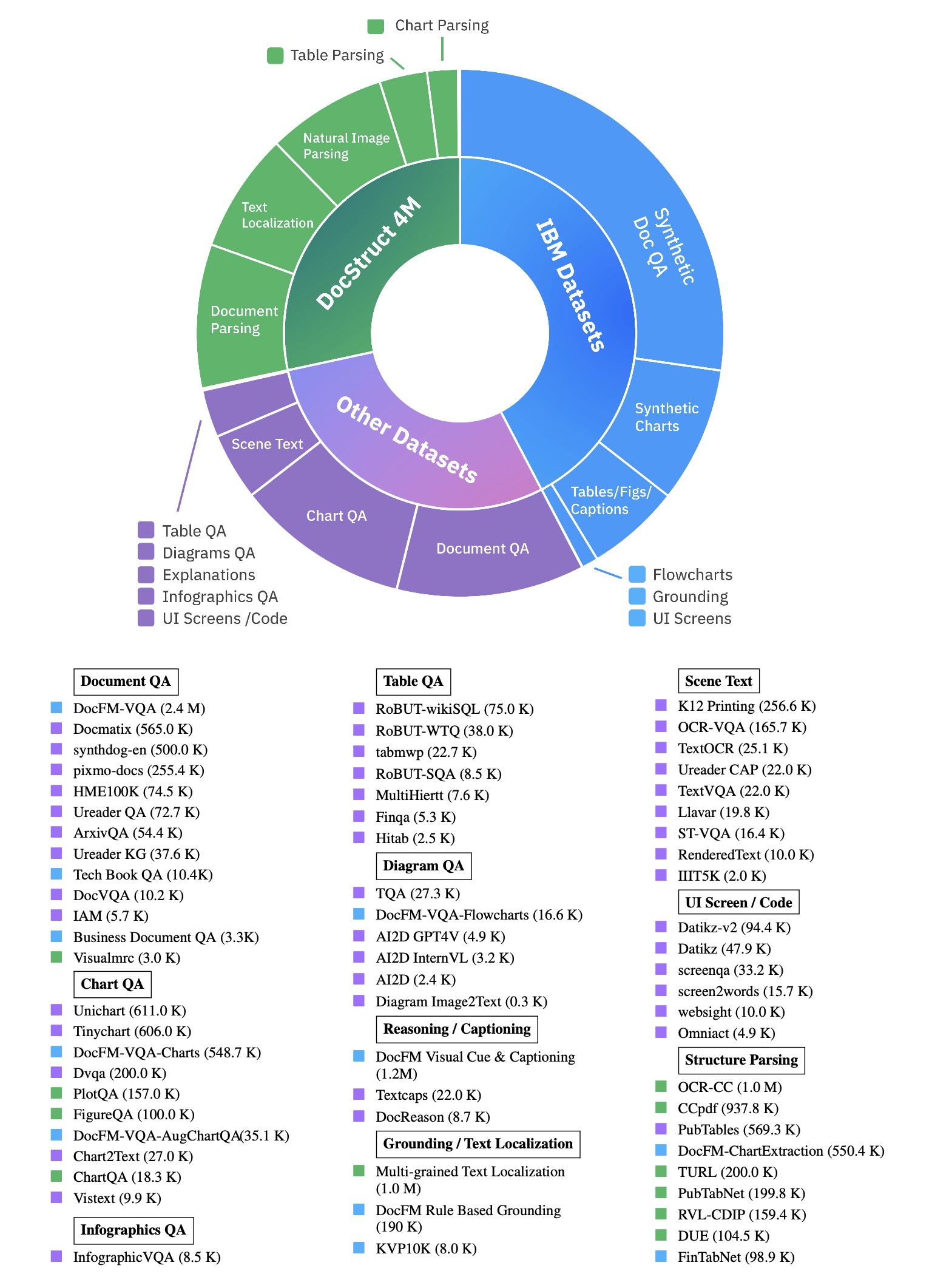
Several interesting datasets were used for Granite Vision training. First is DocFM, a dataset created in IBM and mentioned in previous note on smalDocling model. Granite Vision Team focused on using only a part of DocFM, specifically on synthetic visual QA datasets as a seed for creation synthetic dataset named DocFM verbalization-based VQA (DocFM VQA). Verbalized representation is simply descrption of visual elemnts like charts or pictures, etc. Similarly, next sythetic datasets were created:
- Synthetic Chart VQA, synthetic chart with QA pairs
- Synthetic Flowchart VQA, synthetic flowcharts with QA pairs
- DocFM-ChartExtraction, synthetic dataset for teaching the Granive Vision how to extract data from tables
- DocFM Visual Cue and Captioning,
- DocFM Rule Based Grounding
Full corpus of datasets used for Granite Vision training is in the picture below.
Data preprocessing
Data pre-processing consisted of several annotation and filtering procedures aimed at ensuring compliance with regulatory and safety standards as well as improving data quality. Restricted Data removal: All public datasets were subject to a legal review to detect any potential licensing or PII-related risks. Data with unclear usage rights or originating outside the US was excluded. CSAM removal: State-of-the-art NSFW detection systems were applied to eliminate all Child Sexual Abuse Material. Face blurring: All visual PII was obfuscated by applying automated face-blurring techniques. Deduplication: To avoid redundancy across merged collections, duplicate records were removed. Detection relied on exact pixel matching and perceptual hash methods to account for minor variations, as well as identification of duplicate text entries.