Introduction
OCR on documents remains a challenging task. While printed text can often be recognized with 95% or higher accuracy, real-world documents — containing handwriting, non-standard layouts, and other irregularities — are still much harder to read accurately. There are high quality systems solving documents reading in sub-tasks: OCR, layout analysis, structure recognition, classification.
Recent trend is using large vision-language models to solve whole convertion task in one shot, and giving the user opportunity to define additional specific tasks to do in the prompt.
This post is about SmalDocling, a very tiny and compute-effient vision-language model doing the convertion task and the instruction task written into a prompt. The post is based on SmolDocling research paper.
Architecture
SmolDocling model comes from family of Hugging Face’s SmolVLM. It was trained on datasets allowing for recognition of captions, charts, forms, code, equations, tables, footnotes, lists, page footers & headers, section headings, and text. SmolDocling does OCR on elements mentioned and recognizes the type and location. And here we have main task of SmolDocling - conversion and docuemnt understanding.
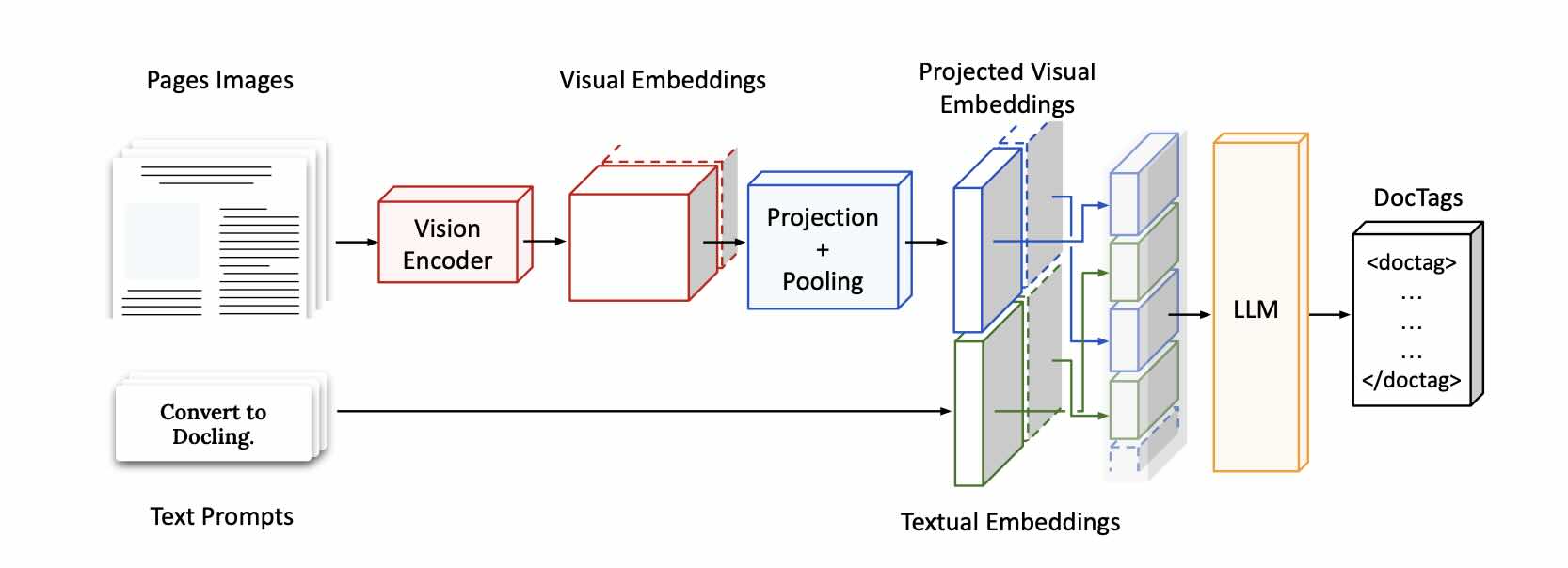
The red cube named as Vision Encoder on the picture above is the image encoder used in SmolVM models, SigLIP-base path-16/512 (93M). It comes from Google’s CLIP-style image encoders — replacing CLIP’s (OpenAI) contrastive softmax loss with a sigmoid cross-entropy loss (this change makes training more stable and more accurate when matching images and text). Its superpowers are low-memory and fast inference. Those superpowers are used here for multimodal reasoning tasks.
Usage
We can get bigger SmolDocling model (), or any large vision-language model to quickly get higher accuracy but also ‘heavier’ inference and so much bigger usage of compute.
SmolDocling can find right niche for deployments on edge devices or on any resource-constrained setting. Another usage is quick prototyping and experimentation, it’s always better to start with small and quick models and avoid complexity that comes with a size.
DocTags
Another interesting thing is a standard proposed by smolDocling model - DocTags. It is created to use efficiently in inference and to train VLMs in a standardized way. HTML and Mardown formats are ambigous and by do not keep document layout context. DocTags separates text content from layout of document which bring clarity. DocTags has also clear and concise format which saves tokens and thus, inference and training on VLMs. See the basic example:
HTML:
<h1>Invoice</h1><p>Customer Name: John Doe</p>
~20–25 tokens.
DocTags:
<heading>Invoice</heading><para>Customer Name: John Doe</para>
~12–15 tokens.
DocTags leveraged OTLS standard and its full vocabulary. OTSL stands for Optimized Table Structure Language, and it’s specialized markup language designed for keeping table structure information. This choise also bring clarity and saves tokens.
Pre-training datasets
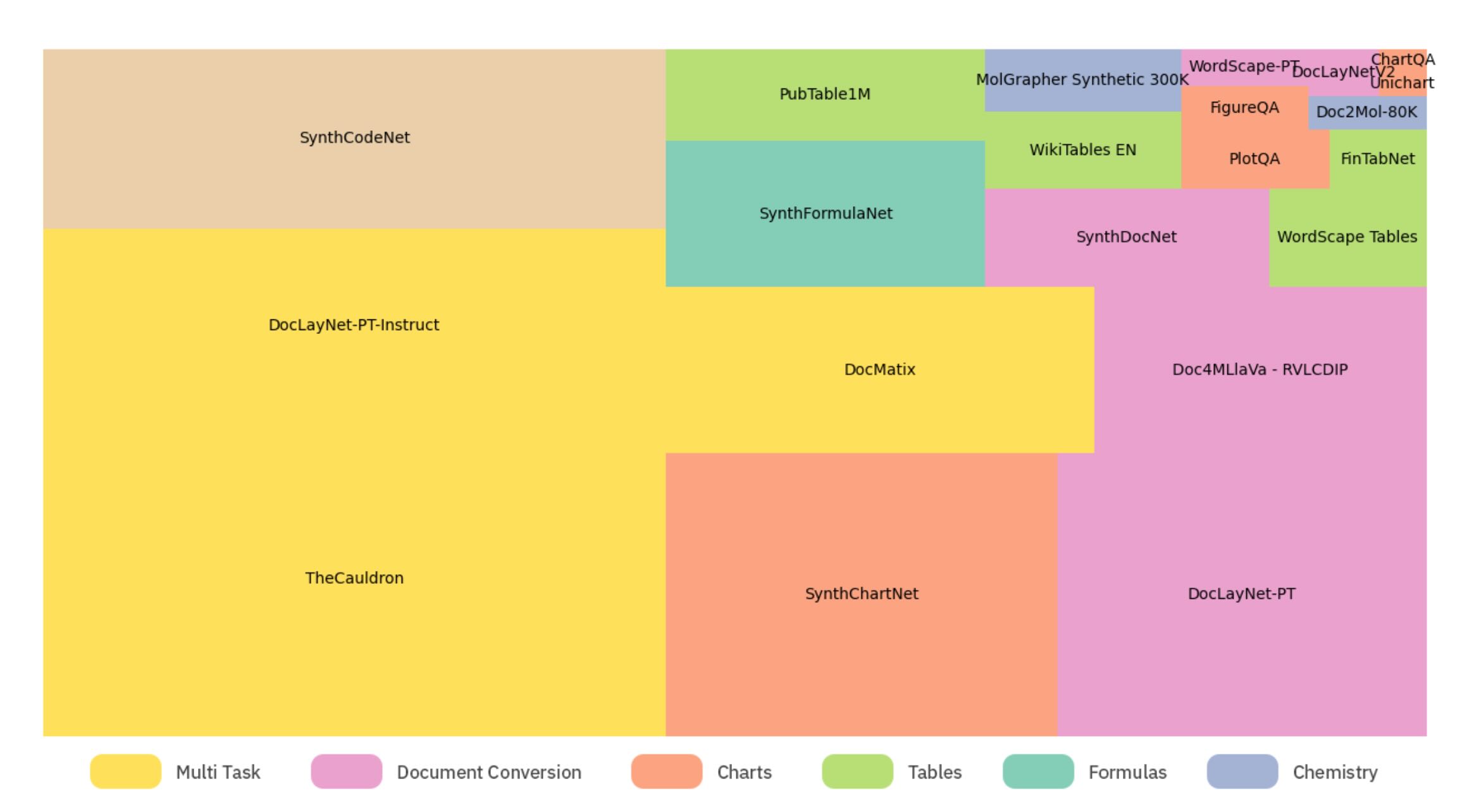
Seeing lack of good multimodal document data SmolDocling team created new public data set: DocLayNet-PT. It contains 1.4M pages from DocFM dataset (PDF documents from CommonCrawl, Wikipedia, business domains).
Original SmolVLM had DocVQA capabilities (Document Visual Question Answering). To keep this feature the smolDocling was trained on Docmatix dataset with added DocTags format information.
Task-specific datasets
The model was also fine-tuned for specific tasks like recognition of layout, tables, charts, code, and equations. For layout and tables the team prepared:
- 76k pages of human annotated and reviewed documets from
DocLayNet-PT(created dataset was namedDocLayNet v2) - 63k pages of tables and text from WordScape dataset
- 250k pages of synthetic annotations from wikpedia for layout, colors and fonts (created dataset was named
SynthDocNet) Tables recognition were covered by fine-tuning withPubTables-1M,FinTabNet,WikiTableSet, and tabular info fromWordScape. Table strcuture information was pushed into OTSL format, so that each cell tag had it’s corresponding structure and text.
Public chart recognition datasets are low quality or not diversified. That triggered creation of anothe dataset containing in total 2.5 million visually diverse charts in 4 categories: line, pie, bar, and stacked bar. SmolDocling team created also code recognition dataset addressing lack of datasets containing code as images. The dataset includes 9.3 million code snippets rendered at 120 dpi. Another dataset was created regarding mathematical formulas: using 730k unique formulas from publi datasets and collecting 4.7 million formulas from arXiv. Final equations dataset contains 5.5 million unique formulas rendered at 120 dpi.
Experiments
To enhance recognition of specific elements and to introduce ability to write no-code instructions to smolDocling model the team has put rule-based techniques and Granite-3.1-2b-instruct model. Random elements were taken from DocLayNet-PT and according instructions for this element were created, something like: “Perform OCR at bbox”, or “Identify page element type at bbox”. Training with Cauldron was applied to avoid catastrophic forgetting.
The model was trained on:
- 64 NVIDIA A100 80GB GPUs,
- one epoch lasting 38 hours, 4 epochs in total.
- optimizer: AdamW
- learning rates: 2x 10^-4, 2x10^-6
- gradient clipping: 1.0
- warmup ratio 0.03
Achieved inference efficiency:
- page conversion time: 0.35 seconds
- memory usage: 0.489GB VRAM
- max sequence length: 8192 tokens
- the model cam process 3 pages at a time
SmolDocling is a small but efficient vision-language model for document conversion. It produces rich structured output in a single pass, which reduces error accumulation compared to multi-stage systems. The model can link captions to images, preserve code formatting, and remove redundant headers or footers. Typical issues include missing tags, malformed structure, and repetitive token loops. Future work should improve page element localization for better accuracy. Overall, SmolDocling shows that compact models with optimized formats can rival much larger models in multi-task document understanding.